
Kapitalismus ohne Wachstum?
ein Ort für Idylle und Utopie
Kapitalismus ohne Wachstum?
MIt Dana Jestel habe ich auf dem Degrowthkongress im September 2014 in Leipzig einen Workshop durchgeführt.
Mit guten Gründen wächst die Kritik am Wachstum an allen Enden, aber ein nahe liegendes Feld dieser Kritik bleibt merkwürdig ausgespart: das Bevölkerungswachstum – so auch auf den Degrowth-Kongressen. Weiterlesen „Bevölkerungswachstum, Commons und Solidarität“
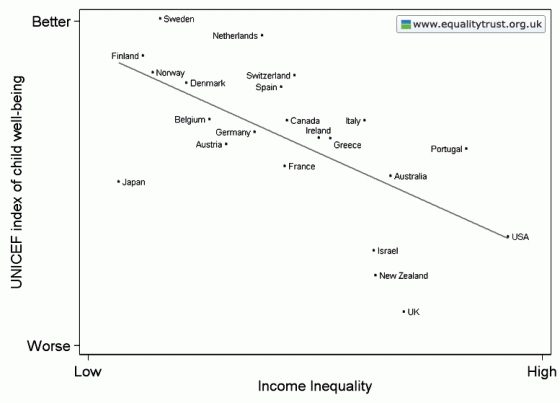
Eigentlich heißt das Thema des gerade vom 24.-26.6.13 an der TU in Berlin stattfindenden Kongresses ja „Umverteilen Macht Gerechtigkeit„, aber die Formulierung mit dem Glück fasst den Eröffnungsvortrag von Richard Wilkinson ganz gut zusammen. Er hat in einer empirischen Studie aufgezeigt, dass wesentliche Faktoren der Lebensqualität in den reicheren Ländern durch eine weitere Steigerung des Wohlstands (BIP) kaum mehr gesteigert werden können, wohl aber – und zwar beträchtlich – durch eine gleichmäßigere Einkommensverteilung. Weiterlesen „Umverteilen Macht Glück“

Die Konferenz der Linken interessierte mich, weil sie, wie die ganze Plan-B-Initiative, sich genau das Thema stellt, das uns auch in einem Arbeitskreis des Instituts Solidarische Moderne beschäftigt: die Perspektiven eines sozial-ökologischen Umbaus auszuloten.
Insgesamt fand ich die Veranstaltung anregend und fruchtbar, habe dabei aber den derzeit eher als altmodisch geltenden Einzelvorträgen mehr Perspektiven entnehmen können als den Plena und Arbeitsgruppen (WorldCafe).
Gregor Gysi, der ja viele Reden halten muss, brachte gleichwohl eine ordentliche Skizze des linken Projektes für einen ökologisch-sozialen Umbau zuwege.
Vor allem war ich aber angetan von den Perspektiven, die Nicole Bullard mit „Einige Gedanken darüber, wie die deutsche Linke die Welt verändern (helfen) kann“ eröffnete und von den Überlegungen, insbesondere zu Krise und Kapitalismus, von Raoul Zelik.
Katja Kipping hatte keine so bahnbrechenden Neuigkeiten, aber sie punktete wie immer mit Charme und, besonders bei mir, mit dem Bekenntnis, dass Politiker zumindest gelegentlich auch fiktionale Texte zur Orientierung zu Hilfe nehmen sollten.
